This page has been moved to abigail.github.io
Tag: c
Perl Weekly Challenge 100: Fun Time
You are given a time (12 hour / 24 hour).
Write a script to convert the given time from 12 hour format to 24 hour format and vice versa.
Ideally we expect a one-liner.
Examples
Example 1
Input: 05:15 pm or 05:15pm
Output: 17:15
Example 2
Input: 19:15
Output: 07:15 pm or 07:15pm
Overview
We have to do three things:
- Parse the input and extract the interesting parts (hours, minutes,
am/pm/none). - Calculate the result. Note that the minutes part stays as is, this doesn’t change whether the time is using am/pm or a 24 hour clock.
- Print the resulting time.
For the am/pm marker, note that if the input uses am or pm, then the output doesn’t. If the input doesn’t have am or pm (that is, it uses a 24 hour clock), then the output will have either am or pm. In particular, it will have am in the output if the input hour is less than 12, else it will have pm.
For the hours, it’s important to realize that a time with am or pm doesn’t use the 0 hour — instead it uses 12. So, beside adding/subtracting 12 (if going from/to pm time), we have to compensate for this. We do this as follows:
- We start off with taking the hour modulo 12. The effect of this is that if the start time uses
amorpm, and the hour is12, the hour now is0. If the start time is in24hour format, we now have hours in range0–11. - If the start time used
pm, we add12to the hour. - If the start time was in
24hour format, and the hour is0(after the modulo12), set the hour to12.
Solutions
For each of the languages, we assume the input is on standard input, one time per line. Output is written to standard output, one time per line.
Perl
We will use a substitution regular expression to modify the time, with an executable replacement part:
say s {^\s* ([0-9]+) : ([0-9]+) \s* ([pa]?)m? \s*\n}
{sprintf "%02d:%02d%s",
$3 ? ($1 % 12) + (lc ($3) eq "a" ? 0 : 12)
: ($1 % 12) || 12,
$2,
$3 ? ""
: $1 >= 12 ? "pm" : "am"}xeir
From the input, we parse the hours (the first ([0-9]+)), the minutes (the second ([0-9]+)) and the am/pm setting (if any) (([pa]?)m?). The result is that $1 contains the hours; $2 contains the minutes, and $3 is either a (for an am time), p (for a pm time) or the empty string (for a time using 24 hours).
In the replacement part, we use sprintf to do formatting: hours and minutes as two digit numbers (0 padded) (%02s), followed by either am, pm, or none. The new hours and am/pm marker are calculated as explained in the overview section.
We’re using four regexp modifiers:
xmeans we can freely have white space in the pattern, which won’t be matched.emeans the replacement part is code which needs to be executed — the result is the replacement.imeans we will be doing the matching case insensitive (so we accept bothamandAM, andpmandPM).rmeans we don’t modify the original string, instead, we return the result. And this result is passed directly tosprintf.
Does this count as a one-liner? I say it does; the newlines are just there for readability.
Find the complete program on GitHub.
Perl Weekly Challenge 100: Triangle Sum
You are given triangle array.
Write a script to find the minimum path sum from top to bottom.
When you are on index `i` on the current row then you may move to either index `i` or index `i + 1` on the next row.
Examples
Example 1
Input: Triangle = [ [1], [2,4], [6,4,9], [5,1,7,2] ]
Output: 8
Explanation: The given triangle
1
2 4
6 4 9
5 1 7 2
The minimum path sum from top to bottom: 1 + 2 + 4 + 1 = 8
[1]
[2] 4
6 [4] 9
5 [1] 7 2
Example 2
Input: Triangle = [ [3], [3,1], [5,2,3], [4,3,1,3] ]
Output: 7
Explanation: The given triangle
3
3 1
5 2 3
4 3 1 3
The minimum path sum from top to bottom: 3 + 1 + 2 + 1 = 7
[3]
3 [1]
5 [2] 3
4 3 [1] 3
Overview
We will read in the data, and put it in a (2-dimensional) array. We will then work from bottom to top, calculating for each point, the minimum path length to the bottom. We can do this by adding the minimum of the two elements "below" the current element to it.
For instance, assume the input is:
3
3 1
5 2 3
4 3 1 3
we can calculate the minimum path length to the bottom for the penultimate row by, for each element in that row, adding to it the minimum of the two elements below. This results in:
3
3 1
8 3 4
4 3 1 3
In the same way, we can calculate the minimum path length for each element in the second row:
3
6 4
8 3 4
4 3 1 3
One more step, and we get the wanted result in the top of the triangle:
7
6 4
8 3 4
4 3 1 3
This clearly is a linear time algorithm.
Solutions
Each of the solutions assumes a single triangle on standard input, one row per line, numbers separated by white space. We’re assuming the numbers are integers. The result, as single number, will be written on standard output.
Perl
We start with reading in the data, which can be done in a single statement:
my @nums = map {[/-?[0-9]+/g]} <>;
For each line of input, we’re extracting the numbers using a simple regular expression. This stores the triangle of numbers in the array @nums; each element of @nums is an array with numbers (a row in the triangle).
We can now calculate the lengths using a nested loop; the other loop loops over the rows (bottom to top, starting with the penultimate row), the inner loop loops over the elements of a row.
for (my $x = @nums - 2; $x >= 0; $x --) {
foreach my $y (keys @{$nums [$x]}) {
$nums [$x] [$y] +=
$nums [$x + 1] [$y] < $nums [$x + 1] [$y + 1]
? $nums [$x + 1] [$y] : $nums [$x + 1] [$y + 1]
}
}
For each element, we adding the minimum of the two elements below it.
All what needs to be done is to print the result:
say $nums [0] [0];
Find the complete program on GitHub.
Feature Compare: Characters to Code Points
In this article we are going to compare how to converts characters/single character strings to their ASCII or Unicode code points in various languages.
For instance, character "A" has code point 65, character "~" has code point 126, and character "ด" has code point 3604.
AWK
AWK doesn’t have any buildins to do these mappings, but it does have sprintf, which can be used to map a number to a single string character:
char = sprintf "%c", codepoint
To map characters to code points, we need to do some preprocessing. For instance, if we need to map printable ASCII characters to code points, we may want to do:
BEGIN {
for (o = 32; o < 127; o ++) {
c = sprintf ("%c", o)
ord [c] = o
}
}
Now in the rest of the program, we can do:
codepoint = ord [char]
assuming that char is a printable ASCII character.
Do note that AWK does not know about Unicode, but gAWK (GNU AWK) does.
Example (gAWK)
BEGIN {
for (o = 32; o < 3700; o ++) {
c = sprintf ("%c", o)
ord [c] = o
}
}
BEGIN {
print ord ["A"] # Prints: 65
print ord ["ด"] # Prints: 3604
printf "%c\n", 70 # Prints: E
printf "%c\n", 3604 # Prints: ด
}
Bash
For bash, we need to resort to printf. It behaves more or less like printf(1). And printf(1) has subtle differences between implementations on BSD and GNU. And this is a bit of a problem. Where as in the GNU implementation, the %c format takes an integer, and returns the character with that code point, while on BSD, the %c format takes a string, and returns the first character. This makes that we cannot use the %c format to map code points to characters.
But the printf buildin (and printf(1)) has a feature not present in the C implementation of printf(3): if the format string contains "\xHH", for some hexadecimal number HH, then this is mapped to the ASCII character with HH as code point.
So, to turn a code point into a character, we’re going to use printf twice. First to create a string with a "\xHH" escape, and then another printf to turn this into a character:
printf -v char "\x$(printf %x $codepoint)"
This takes the code point in $codepoint, and places the corresponding character in $char.
To go from a character to a code point, we need to use another feature of the printf buildin/printf(1) utility: if an argument of printf starts with single or double quote, the value is the code point of the first character following the quote. Note that we have to be careful to use this syntax, as the quote character itself is special to the shell — we need to escape it.
We can then use the following:
printf -v codepoint "%d" "'$char"
This takes the character in the variable $char, and places the corresponding code point into $codepoint.
Example
printf "%d\n" "'A" # Prints: 65
printf "\x$(printf %x 70)\n" # Prints: F
C
In C, characters are code points: a string is just an array of numbers, where each number is the corresponding code point. So we can just use:
ch [0] = codepoint;
codepoint = ch [0];
where codepoint contains the code point, and ch is a string (of type char *, and appropriately malloc -ed).
Single quote characters are also just code points, so we can also things like:
codepoint = 'A';
Example
char ch [3];
ch [0] = 70;
ch [1] = 'G';
ch [2] = '\0';
printf ("%d\n", 'A'); /* Prints: 65 */
printf ("%s\n", ch); /* Prints: FG */
Lua
In Lua, there are methods char and byte in the string module to map between characters and code points:
char = string . char (codepoint)
codepoint = string . byte (char)
The string module does not have to be explicitly loaded.
Example
print (string . byte ("A")) -- Prints: 65
print (string . char (70)) -- Prints: F
Node.js
Node.js has methods fromCodePoint and codePointAt in the String module to map between code points and code points:
char = Strings . fromCodePoint (codepoint, ...)
codepoint = char . codePointAt (0)
Note that fromCodePoint is called as a method in the String module, while codePointAt is called on a string. The latter takes a parameter, indicating from which position of the string we want the code point.
Node.js also as fromCharCode and charCodeAt which are subtly different. Node.js works with UTF-16, which means each character is encoded as one or two 16-bit units. While fromCodePoint and codePointAt deal with Unicode code points, fromCharCode andcharCodeAt deal with those 16-bit units. This only becomes relevant for code points outside of the Basic Multilingual Plane; that is, for code points exceeding U+FFFF (65535).
The String module does not to be loaded explicitly.
Example
console . log ("A" . codePointAt (0)) // Prints: 65
console . log ("ด" . codePointAt (0)) // Prints: 3604
console . log (String . fromCodePoint (70)) // Prints: F
console . log (String . fromCodePoint (70, 72, 74)) // Prints: FHJ
console . log (String . fromCodePoint (3604)) // Prints: ด
Perl
Perl has chr which takes a code point and returns the corresponding character, and ord which takes a character and returns the corresponding code point:
$char = chr $codepoint;
$codepoint = ord $char;
This works for all Unicode characters.
Example
say ord "A"; # Prints: 65
say ord "ด"; # Prints: 3604
say chr 70; # Prints: F
say chr 3604; # Prints: ด
char = chr (codepoint)
codepoint = ord (char)
In Python 2, this works for characters with code points up to 255; Python 3 supports the full Unicode range.
Example
print (ord ("A")) # Prints: 65
print (ord ("ด")) # Prints: 3604
print (chr (70)) # Prints: F
print (chr (3604)) # Prints: ด
char = codepoint . chr
codepoint = char . ord
Without arguments, chr only works on numbers 0 - 255, giving a range error on larger numbers. To make use of the full Unicode range, pass in the encoding:
char = codepoint . chr (Encoding::UTF_8)
Example
puts "A" . ord # Prints: 65
puts "ด" . ord # Prints: 3604
puts 70 . chr # Prints: F
puts 3604 . chr (Encoding::UTF_8) # Prints: ด
Perl Weekly Challenge 97: Binary Substrings
You are given a binary string $B and an integer $S.
Write a script to split the binary string $B of size $S and then
find the minimum number of flips required to make it all the same.
Overview
Just like in this weeks other challenge, we will use a command line parameter. We will use -s SIZE to indicate the size of the substrings. The binary strings will be read from standard input.
To calculate the minimum number of flips required, note that flipping a bit on position i of a sub string has no bearing on the flips required in any other position. So we can calculate the minimum number of flips required for each position i independently, and sum the totals.
To calculate the minimum number of flips required for a specific position i, we calculate the number of 0s in position i in all the sub strings. Given the number of 0s, we can calculate the number of 1s as both numbers should add up to the number of sub strings (and that number can be easily calculate by dividing the length of the binary string with the length of the sub strings). Now, the minimum number of flips required is the minimum of the number of 0s and the number of 1s. Observe that is may be possible we end up flipping to a string which is not one of the sub strings. Consider the binary string 111011011011, and sub string length of 4. Then we get the following sub strings:
1110
1101
1011
It requires flipping two bits to change one of the sub string to any of the others, so four flips would be required if the target where any of the sub strings. However, if we just flip the 0 bits, all sub strings end up being 1111, and only three flips are required.
Note that we don’t have to split the binary string into sub strings to calculate the number of flips. We can just leave the binary string as is, and use a simple formula. The bit at position i of sub string j, is at position j * size + i, where size is the given length of the sub strings. For languages which index strings starting from index 1, the formula is j * size + i + 1.
Solutions
We will not be showing any code related to parsing command line options. This is the same as for the other challenge of this week. In each language, we will have a variable size (or $size) which will contain the value passed in.
The implementation in each language is almost identical, except for some syntax variation.
Perl
while (<>) {
chomp;
my $sections = length () / $size;
my $sum = 0;
for my $i (0 .. $size - 1) {
my $zeros = 0;
for my $j (0 .. $sections - 1) {
my $index = $j * $size + $i;
$zeros ++ if substr ($_, $index, 1) eq "0";
}
my $ones = $sections - $zeros;
$sum += min ($zeros, $ones);
}
say $sum;
}
For each position i, we count the number of 0 on that position. We then calculate the number of 1s in that position, and sum the minimum of the two.
Find the complete program on GitHub.
AWK
{
sum = 0
sections = length ($0) / size
for (i = 0; i < size; i ++) {
zeros = 0;
for (j = 0; j < sections; j ++) {
indx = j * size + i + 1 # Can't use 'index' as a variable
if (substr ($0, indx, 1) == "0") {
zeros ++
}
}
ones = sections - zeros
sum += zeros < ones ? zeros : ones
}
print sum
}
Find the complete program on GitHub.
Bash
while read line
do sections=$((${#line} / $size))
sum=0
for ((i = 0; i < size; i ++))
do zeros=0
for ((j = 0; j < sections; j ++))
do index=$(($j * $size + $i))
if [ "${line:$index:1}" == "0" ]
then zeros=$(($zeros + 1))
fi
done
ones=$(($sections - $zeros))
sum=$(($sum + ($zeros < $ones ? $zeros : $ones) ))
done
echo $sum
done
Find the complete program on GitHub.
C
while ((strlen = getline (&line, &len, stdin)) != -1) {
strlen --; /* We don't care about the newline */
int sections = strlen / size;
int sum = 0;
for (int i = 0; i < size; i ++) {
int zeros = 0;
for (int j = 0; j < sections; j ++) {
int index = j * size + i;
if (line [index] == '0') {
zeros ++;
}
}
int ones = sections - zeros;
sum += zeros < ones ? zeros : ones;
}
printf ("%d\n", sum);
}
free (line);
Find the complete program on GitHub.
Lua
for line in io . lines () do
local sections = #line / size
local sum = 0
for i = 0, size - 1 do
local zeros = 0
for j = 0, sections - 1 do
index = j * size + i + 1
if string . sub (line, index, index) == "0"
then zeros = zeros + 1
end
end
local ones = sections - zeros
if zeros < ones
then sum = sum + zeros
else sum = sum + ones
end
end
io . write (sum, "\n")
end
Find the complete program on GitHub.
Node.js
require ('readline')
. createInterface ({input: process . stdin})
. on ('line', _ => {
let sum = 0
let sections = _ . length / size
for (let i = 0; i < size; i ++) {
let zeros = 0
for (let j = 0; j < sections; j ++) {
let index = j * size + i;
if (_ . substring (index, index + 1) == "0") {
zeros ++
}
}
let ones = sections - zeros
sum += zeros < ones ? zeros : ones
}
console . log (sum)
});
Find the complete program on GitHub.
Python
for line in fileinput . input ():
sections = len (line) / size
sum = 0
for i in range (size):
zeros = 0
for j in range (sections):
index = j * size + i
if line [index : index + 1] == "0":
zeros += 1
ones = sections - zeros
sum += min (zeros, ones)
print (sum)
Find the complete program on GitHub.
Ruby
ARGF . each_line do |line|
sections = (line . length - 1) / size
sum = 0
for i in 0 .. size - 1 do
zeros = 0
for j in 0 .. sections - 1 do
index = j * size + i
if line [index, 1] == "0"
then zeros += 1
end
end
ones = sections - zeros
sum += [zeros, ones] . min
end
puts sum
end
Find the complete program on GitHub.
Perl Weekly Challenge 97: Ceasar Cipher
You are given string $S containing alphabets A..Z only and a number $N.
Write a script to encrypt the given string $S using Caesar Cipher with left shift of size $N.
Overview
Wikipedia has a description of the Ceasar Cipher.
First thing we need to define is how to read the input. We’ve decided to read the plain text from standard input, and we use a command line option (-s SHIFT) to indicate the left shift. The encrypted text will be written to standard output.
Shifting will be done by looking at each characters, and if it is a capital letter, we look at its code point (ASCII or Unicode — which for letters A to Z is identical), and subtract the left shift. If the result is less than 65, we add 26. 65 being the code point of A, and 26 the number of letters. We than map the resulting code point back to a character.
Solutions
Perl
use Getopt::Long;
GetOptions 's=i' => \my $shift;
die "-s SHIFT option required" unless defined $shift;
$shift %= $NR_OF_LETTERS;
We first parse to the command line. Getopt::Long does the work of parsing @ARGV for us. If no option is given, we die. Else, we mode the value (now in $shift) with 26, because shifting by 26 is a no-op.
We can now do the actual shifting:
my $NR_OF_LETTERS = 26;
my $ORD_A = ord ('A');
while (<>) {
chomp;
s {([A-Z])}
{ my $ch = ord ($1) - $shift;
$ch += $NR_OF_LETTERS if $ch < $ORD_A;
chr $ch
}eg;
say;
}
We iterate over the input, and for each capital letter found, we take its code point (ord), and subtract the given shift value. We add 26 if we end up below the code point of the letter A. Then we translate the number back to a (one letter) string (chr).
Find the complete program on GitHub.
AWK
AWK does not have a method to map a character to its code point. We therefor start by building an array (ord), so we can look up the code point. In AWK, we can index arrays with strings:
BEGIN {
NR_OF_LETTERS = 26
ORD_A = 65
for (i = ORD_A; i < ORD_A + NR_OF_LETTERS; i ++) {
t = sprintf ("%c", i)
ord [t] = i
}
}
We then need to parse the command line option:
BEGIN {
for (i = 1; i < ARGC; i ++) {
if (ARGV [i] == "-s") {
shift = ARGV [i + 1]
}
}
ARGC = 0
}
ARGC is the number of elements in ARGV, which, unlike most arrays in AWK, is indexed starting from 0. We’re scanning the array starting from index 1, as ARGV [0] contains the name of the executable (typically awk).
Note the assignment ARGC = 0. If we don’t do this, awk itself will treat the options as subsequent files to be executed.
Now the shifting of the characters:
{
out = ""
for (i = 1; i <= length (letters); i ++) {
char = substr ($0, i, 1)
if (ord [char]) {
n = ord [char] - shift
if (n < ORD_A) {
n = n + NR_OF_LETTERS
}
char = sprintf ("%c", n)
}
out = out char
}
print out
}
AWK does not have a direct way of mapping a code point to a string (like chr in Perl and several other languages), but it does have sprintf, which has a %c specifier in the format, which does exactly that job. With AWK, sprintf works exactly the same as its C counterpart.
Find the complete program on GitHub.
Bash
First, getting the option:
while getopts "s:" name
do if [ "$name" = "s" ]
then shift=$OPTARG
fi
done
Bash (and the Bourne Shell) has a getopts buildin, which parses command line options. Here, we’re using the format "s:" to indicate we’re looking for a -s parameter with a mandatory option. We can iterate over the results of getopts, which sets the option in a variable $name in each iteration. The value belonging to that option is in $OPTARG.
To shift the characters, we use a different algorithm that we’re using in the other languages. Bash doesn’t have easy methods to get the code point of a character, or to get the character given a code point. So, we’re using tr to shift the text one character to the left — and we do this as often as needed:
while read line
do for ((i = 0; i < $shift; i ++))
do line=`echo $line | tr A-Z ZA-Y`
done
echo $line
done
Find the complete program on GitHub.
C
C has a getopt function, which like the Bash buildin, can be iterated over. It takes the same format string as we used in Bash, "s:", indicating a -s parameter taking an option. It take two further arguments, a number argc and an array of strings argv; the first is the length of the array argc, and argv contains the name of the program as the first element, and the arguments to the program as subsequent elements. Typically, argc and argv are just copied from the parameters to main ():
int main (int argc, char ** argv) {
int ch;
int shift = -1;
int NR_OF_LETTERS = 26;
while ((ch = getopt (argc, argv, "s:")) != -1) {
switch (ch) {
case 's':
shift = atoi (optarg) % NR_OF_LETTERS;
break;
}
}
if (shift < 0) {
fprintf (stderr, "Requires an -s parameter\n");
exit (1);
}
C doesn’t automagically convert between integers and strings, so we’re calling atoi on the -s argument; atoi takes a string, and returns an integer.
In C, strings are just arrays of numbers, so shifting is easy. We can directly modify the numeric value in the array. We’re using getline to read lines from standard input. We’re then using a moving pointer, line_ptr to look (and modify) each character in the string line. If line_ptr points to a capital letter — which we check using the function isupper, we shift the character the required amount:
while ((strlen = getline (&line, &len, stdin)) != -1) {
char * line_ptr = line;
while (* line_ptr) {
if (isupper (* line_ptr)) {
* line_ptr -= shift;
if (* line_ptr < 'A') {
* line_ptr += NR_OF_LETTERS;
}
}
line_ptr ++;
}
printf ("%s", line);
}
Find the complete program on GitHub.
Lua
In our Lua solution, we’re parsing the command line arguments ourselves. The array with arguments is called arg, and prefixing an array with # gives its size:
local NR_OF_LETTERS = 26
local shift = -1
if #arg == 2 and arg [1] == "-s"
then shift = arg [2] % NR_OF_LETTERS
end
if shift < 0
then io . stderr : write ("Requires a '-s SHIFT' option\n")
os . exit (1)
end
We define a function to shift a capital character; it takes two arguments, char, the character to be shifted, and shift, the distance to shift:
local ORD_A = string . byte ("A")
function do_shift (char, shift)
local n = string . byte (char) - shift
if n < ORD_A
then n = n + NR_OF_LETTERS
end
return string . char (n)
end
Note the byte and char functions from the string class. The first returns the code point of the character passed in; the latter does the reverse, returning the character of the code point passed in.
We then iterate over the input, and use the gsub method to shift capital letters. gsub does a global substitution, and can take a function as parameter. If so, for each match, the function is called, and its return value is used as the substitution part. This is more or less equivalent to Perls s///e.
for line in io . lines () do
io . write (string . gsub (line, "[A-Z]", function (ch)
return do_shift (ch, shift)
end), "\n")
end
Find the complete program on GitHub.
Node.js
Node.js has an impressive module to parse command line arguments, yargs, which we will be using the parse the command line:
const argv = require ('yargs')
. option ('s', {
type: 'number',
})
. demandOption ('s')
. argv;
const shift = argv . s
A function to shift an individual character:
const NR_OF_LETTERS = 26
const ORD_A = "A" . charCodeAt (0)
function shift_char (char, shift) {
if (char . match (/[A-Z]/)) {
let n = char . charCodeAt (0) - (shift % NR_OF_LETTERS)
if (n < ORD_A) {
n = n + NR_OF_LETTERS
}
return String . fromCharCode (n)
}
else {
return char
}
}
Note that here, unlike with our Lua solution, the function is called for any character in the input, so we need an additional check so we only shift capital letters. To get the code point of a character, we call charCodeAt; to get the character given a code point, we use fromCharCode.
To process the input, we split each line into individual characters, call shift_char on each of them, then join the return values back to a string:
require ('readline')
. createInterface ({input: process . stdin})
. on ('line', _ =>
console . log (_ . split ("")
. map (_ => shift_char (_, shift))
. join ("")))
Find the complete program on GitHub.
Python
Python has a getopt module which has a getopt function which is similar to the one used in C and Bash. (Python also has argparse, but we stick with something we’re more familiar with).
NR_OF_LETTERS = 26
shift = -1
opts, args = getopt . getopt (sys . argv [1:], 's:')
for opt, val in opts:
if opt == "-s":
shift = int (val) % NR_OF_LETTERS
sys . argv [1:] = []
if shift < 0:
sys . stderr . write ("Argument -s SHIFT is required\n")
sys . exit (1)
Note the assignment sys . argv [1:] = [], this clears the argv array. That way, we will be reading from standard input instead of Python trying to open a file called -s.
Strings are immutable in Python, so we will be construction a new string, with the capital letters shifted:
for line in fileinput . input ():
out = ""
for i in range (len (line)):
if "A" <= line [i] <= "Z":
n = ord (line [i]) - shift
if n < ORD_A:
n = n + NR_OF_LETTERS
out += chr (n)
else:
out += line [i]
sys . stdout . write (out)
Find the complete program on GitHub.
Ruby
Ruby has the optparse module to parse command line parameters. This supplies a method getopts which returns an hash with options and their values.
require 'optparse'
NR_OF_LETTERS = 26
params = ARGV . getopts ('s:')
shift = params ["s"] ? params ["s"] . to_i % NR_OF_LETTERS : -1
if shift < 0
STDERR . puts "Requires a -s SHIFT option"
exit 1
end
We’re using to_i to make the parameter a string.
A function to shift a capital letter:
def shift_letter (letter, shift)
n = letter . ord - shift
if n < 'A' . ord
then n = n + NR_OF_LETTERS
end
return n . chr
end
We’re iterating over the input, and are using gsub to replace each capital letter with a shifted one:
ARGF . each_line do |line|
line = line . gsub (/[A-Z]/) {|_| shift_letter _, shift}
puts line
end
Find the complete program on GitHub.
Perl Weekly Challenge 96: Edit Distance
You are given two strings $S1 and $S2.
Write a script to find out the minimum operations required to convert $S1 into $S2. The operations can be insert, remove or replace a character. Please check out [the] Wikipedia page for more information.
Overview
What we are asked to do, is to calculate the Levenshtein distance between two strings. If we have two strings, $source and $dest, we can recursively define how to go from $source to $dest using inserts, deletes, and replacements. Let head ($str) be the first character of a string $str, and tail ($str) be the string, except the first character. Then:
- If
$sourceis the empty string, we add each of the characters of$dest. - If
$destis the empty string, we delete each of the characters of$source. - If
head ($source)equalshead ($dest), then we recurse withtail ($source)andtail ($dest). - Otherwise, we either:
- add
head ($dest), and recurse with$sourceandtail ($dest). - delete
head ($dest), and recurse withtail ($source)and$dest. - replace
head ($source)withhead ($tail), and recurse withtail ($source)andtail ($dest).
- add
Since we just want to number of operations, we can translate this. Let 

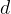

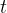
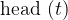
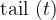

We can rearrange this. Define 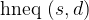
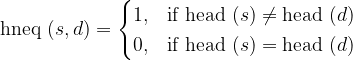
That is, 1 if the first characters differ, and 0 if they are equal. Then:
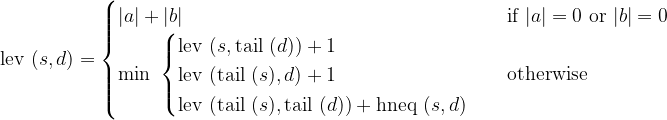
We can use this to construct a recursive algorithm. However, this would require 
We will be calculating a 2-dimensional array distance. distance [i] [j] will be the minimum number of edits required to change the first i characters of the source string (s) to the first j characters of the destination string (d). We then have, in pseudo-code:
for j = 1 .. |d| do
distance [0] [j] = j for j = 1 .. |d|
end
for i = 1 .. |s| do
distance [i] [0] = i for i = 1 .. |s|
done
for i = 1 .. |s| do
for j = 1 .. |d| do
cost = s [i] == d [j] ? 0 : 1
distance [i] [j] = min (distance [i - 1] [j] + 1,
distance [i] [j - 1] + 1,
distance [i - 1] [j - 1] + cost)
done
done
return distance [|s|] [|d|]
Note that strings are indexed 1-based.
This uses 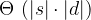
i and i - 1. With a little rearrangement and deletion of rows we no longer use, we can reduce the memory to 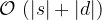
for i = 0 .. |s| do
for j = 0 .. |d| do
if i == 0 || j == 0
then
distance [i] [j] = i + j
else
cost = s [i] == d [j] ? 0 : 1
distance [i] [j] = min (distance [i - 1] [j] + 1,
distance [i] [j - 1] + 1,
distance [i - 1] [j - 1] + cost)
end
end
if i > 0
then
delete distance [i]
end
end
return distance [|s|] [|d|]
By just using two one dimensional arrays, and swapping the strings if the destination string is larger than the source string, we could reduce the memory usage to 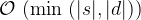
Implementation of the algorithm above in various languages is now easy.
Solutions
Perl
sub LevenshteinDistance ($first, $second) {
my $distance;
for (my $i = 0; $i <= length ($first); $i ++) {
for (my $j = 0; $j <= length ($second); $j ++) {
$$distance [$i] [$j] =
$i == 0 || $j == 0 ? $i + $j
: min ($$distance [$i - 1] [$j] + 1,
$$distance [$i] [$j - 1] + 1,
$$distance [$i - 1] [$j - 1] +
(substr ($first, $i - 1, 1) eq
substr ($second, $j - 1, 1) ? 0 : 1))
}
undef $$distance [$i - 1] if $i;
}
$$distance [-1] [-1];
}
Find the full program on GitHub.
AWK
{
for (i = 0; i <= length ($1); i ++) {
for (j = 0; j <= length ($2); j ++) {
distance [i, j] = i == 0 || j == 0 ? i + j\
: min(distance [i - 1, j] + 1,
distance [i, j - 1] + 1,
distance [i - 1, j - 1] +\
(substr ($1, i, 1) == substr ($2, j, 1) ? 0 : 1))
}
}
print distance [length ($1), length ($2)]
}
Find the full program on GitHub.
C
size_t min3 (size_t a, size_t b, size_t c) {
return a < b ? a < c ? a : c
: b < c ? b : c;
}
size_t LevenshteinDistance (char * first, size_t n,
char * second, size_t m) {
size_t ** distance;
if ((distance = malloc ((n + 1) * sizeof (size_t *))) == NULL) {
fprintf (stderr, "Out of memory\n");
exit (1);
}
for (size_t i = 0; i <= n; i ++) {
if ((distance [i] = malloc ((m + 1) * sizeof (size_t))) == NULL) {
fprintf (stderr, "Out of memory\n");
exit (1);
}
for (size_t j = 0; j <= m; j ++) {
distance [i] [j] = i == 0 || j == 0 ? i + j
: min3 (distance [i - 1] [j] + 1,
distance [i] [j - 1] + 1,
distance [i - 1] [j - 1] +
(first [i - 1] == second [j - 1] ? 0 : 1));
}
if (i) {
free (distance [i - 1]);
}
}
size_t out = distance [n] [m];
free (distance [n]);
free (distance);
return (out);
}
Find the full program on GitHub.
Lua
function LevenshteinDistance (first, second)
local n = first : len ()
local m = second : len ()
distance = {}
for i = 0, n do
distance [i] = {}
for j = 0, m do
if i == 0 or j == 0
then
distance [i] [j] = i + j
else
local cost = 1
if string . sub (first, i, i) ==
string . sub (second, j, j)
then
cost = 0
end
distance [i] [j] = math . min (
distance [i - 1] [j] + 1,
distance [i] [j - 1] + 1,
distance [i - 1] [j - 1] + cost
)
end
end
if i > 0
then
distance [i - 1] = nil
end
end
return distance [n] [m]
end
Find the full program on GitHub.
Node.js
function LevenshteinDistance (strings) {
let first = strings [0] . split ("");
let second = strings [1] . split ("");
let distance = [];
let N = first . length;
let M = second . length;
for (let i = 0; i <= N; i ++) {
distance [i] = [];
for (let j = 0; j <= M; j ++) {
distance [i] [j] =
i == 0 || j == 0 ? i + j
: Math . min (distance [i - 1] [j] + 1,
distance [i] [j - 1] + 1,
distance [i - 1] [j - 1] +
(first [i - 1] ==
second [j - 1] ? 0 : 1))
}
if (i) {
distance [i - 1] = 0
}
}
return distance [N] [M]
}
Find the full program on GitHub.
Python
def LevenshteinDistance (first, second):
n = len (first)
m = len (second)
distance = []
for i in range (n + 1):
distance . append ([])
for j in range (m + 1):
distance [i] . append (i + j if i == 0 or j == 0 else
min (distance [i - 1] [j] + 1,
distance [i] [j - 1] + 1,
distance [i - 1] [j - 1] +
(0 if first [i - 1] ==
second [j - 1] else 1)))
return distance [n] [m]
Find the full program on GitHub.
Ruby
def LevenshteinDistance (first, second)
n = first . length
m = second . length
distance = []
for i in 0 .. n do
distance [i] = []
for j in 0 .. m do
distance [i] [j] = i == 0 || j == 0 ? i + j
: [distance [i - 1] [j] + 1,
distance [i] [j - 1] + 1,
distance [i - 1] [j - 1] +
(first [i - 1] == second [j - 1] ? 0 : 1)] . min
end
if i > 1
distance [i - 1] = nil
end
end
return distance [n] [m]
end
Find the full program on GitHub.
Perl Weekly Challenge 96: Reverse Words
You are given a string $S.
Write a script to reverse the order of words in the given string. The string may contain leading/trailing spaces. The string may have more than one space between words in the string. Print the result without leading/trailing spaces and there should be only one space between words.
Overview
The challenge doesn’t say what a word is. Punctuation typically isn’t part of word, but since the challenge only talks about words and spaces, we will take a simplistic definition of a word: a sequence of non white space characters.
This makes the challenge rather trivial in most languages.
We will reading lines from standard input, and we will treat each line as a line for which the order of the words need to be reversed.
Solutions
Perl
Perl makes it easy; we can to this as a one-liner:
say join " " => reverse /\S+/g for <>;
We’re extracting the words using a regular expression (/\S+/g); due to the /g modifier, and the list context, the matched words are returned. It’s then a matter of reversing the words, and joining them with a single space, before printing the result.
Find the full program on GitHub.
AWK
By default, AWK iterates over the lines of input, and splits each line on white space. The resulting fields are available in variables $1, $2, etc. The number of fields is in the variable NF. There is no function to reverse an array (but since the fields aren’t available in an array, such a functionality would have been marginally useful anyway), nor does AWK have a method to join a list/array of strings. So, we have to write a loop:
{
for (i = NF; i; i --) {
printf "%s%s", $i, (i == 1 ? "\n" : " ");
}
}
Find the full program on GitHub.
Bash
Bash has the useful functionality to read in a line from standard input, and put the different words into an array. There is no functionality to reverse an array, so we have to write a loop:
while read -a words
do
for ((i = ${#words[@]} - 1; i >= 0; i --));
do printf "%s" ${words[$i]}
if (($i == 0))
then printf "\n"
else printf " "
fi
done
done
read reads a line from standard input; the -a option makes that the input is split on white space, and put into an array — in this case words, the argument to read.
${#words[@]} gives use the size of the array words. words[@] is the entire array, and the # prefix gives the length. The ((...)) construct makes that we can do arithmetic on what’s inside.
Find the full program on GitHub.
C
As usual, C makes us work a lot harder. We have to do our own memory management, and there is no native support for pattern matching.
We tackle the problem by reading a line of input at the time, and then, for each line, use a pointer starting from the end of the line working towards the beginning. We then repeatedly skip white space, find the beginning of a word, and print this word.
We start off with some word to even be able to read lines:
# include <stdlib.h>
# include <stdio.h>
# include <ctype.h>
int main (void) {
char * line = NULL;
size_t len = 0;
size_t ptr;
while ((ptr = getline (&line, &len, stdin)) != -1) {
getline reads a line from standard input (or rather, from the stream given as third parameter), placing the result in line. The length of the string is returned by getline, so ptr is the length of the string. Note that the string returned by getline is NUL terminated, but this byte isn’t included in the length. So, line [ptr] is the NUL byte.
We are now going to walk the string backwards. First task is to skip any trailing white space:
size_t output = 0;
while (ptr > 0) {
while (ptr > 0 && isspace (line [ptr - 1])) {
ptr --;
}
We’ll be using the variable output to track whether we have outputted a word or not (see below). The isspace function returns true of the character passed in is a white space character. This is be equivalent to matching the character to /\s/ in languages which support pattern matching.
If we have reached the beginning of the string, we’re done. Otherwise, line [ptr] points to the first white space character after a word, and we will terminate the current line after this word:
if (ptr <= 0) {
break;
}
line [ptr] = '\0';
We now skip to the beginning of the word, and print the result. Since we have put a NUL right after the word, it only prints the word, not the rest of the line. We also print a space first, unless it is the first word we print:
while (ptr > 0 && !isspace (line [ptr - 1])) {
ptr --;
}
printf ("%s%s", output ++ ? " " : "", &line [ptr]);
Find the full program on GitHub.
Lua
In Lua, gmatch can be used to match all occurrences of a pattern in a string. However, this returns an iterator, not an array. We cannot iterate in reverse, nor does lua have native functionality to reverse an array. So, we use gmatch to find all the words, iterate over the results, and build an array — backwards. That is, we put each element to the front of the array.
for line in io . lines () do
local words = {}
for str in string . gmatch (line, "[^%s]+") do
table . insert (words, 1, str)
end
io . write (table . concat (words, " "), "\n")
end
Note that in lua, the escape character in patterns is "%", not "\".
Find the full program on GitHub.
Node.js
In Node.js, the task is easy. It has a trim method which strips leading and trailing white space. There are also split which, given a pattern, splits a string into an array of sub-strings; reverse to reverse the elements in an array, and join to join an array of strings into a single string:
require ('readline')
. createInterface ({input: process . stdin})
. on ('line', _ =>
console . log (_ . trim ()
. split (/\s+/)
. reverse ()
. join (" ")))
Find the full program on GitHub.
Python
Python makes live easy as well. Its strip method removes leading and trailing white space. split without arguments splits a string on white space. reverse reverses an array, and join joins an array. join is a bit peculiar in that it is a method on the separator, taking an array as argument.
import fileinput
for line in fileinput . input ():
words = line . strip () . split ()
words . reverse ()
print (" " . join (words))
Find the full program on GitHub.
Ruby
Ruby has a strip method to get rid of leading and trailing white space. split can be used to split a string on white space. reverse reverses an array, and join joins an array resulting in a string we can print.
ARGF . each_line do |l|
puts (l . strip . split (/\s+/)) . reverse . join (" ")
end
Find the full program on GitHub.
Perl Weekly Challenge 95, Part 2
Write a script to demonstrate Stack operations like below:
push($n)– add$nto the stackpop()– remove the top elementtop()– get the top elementmin()– return the minimum element
This challenge starts off normal; push, pop, and top are regular stack operation, but it takes an unexpected twist at the end. min is not a regular stack operation. In fact, it’s not a stack operation at all. If you need a datastructure where you need to find the minimum value, a stack is a horrible choice. You ought to be using a heap, or a balanced tree instead.
Solutions
For all solutions, we let top and min print an error message if the are called on an empty stack. pop on an empty stack is a no-op.
Our input consists of a set of commands, one command per line. pop, top and min won’t take arguments, while push will be followed by a space, and the number to be pushed. There won’t be parenthesis in the input.
Perl
Perl has push and pop operations, which act on arrays, where the last element of the array acts as the top of the stack. For the min operation, we will use the min function from List::Util module:
use List::Util 'min';
my $ERROR = "Stack is empty";
my @stack;
while (<>) {
if (/^push\s+(.*)/) {push @stack => $1}
if (/^pop/) {pop @stack}
if (/^top/) {say $stack [-1] // $ERROR}
if (/^min/) {say min (@stack) // $ERROR}
}
Find the complete program on GitHub.
Node.js
Node.js has push and pop methods, which, just like in Perl, act on arrays. The last element of the array acts as the top of the stack. For the min operator, we make use of Math . min.
We iterate over the input, and process each line as follows (at this point, command contains the line of input, stripped from its newline):
let stack = [];
let ERROR = "Stack is empty";
{
let [m, operator, value] =
command . match (/^(push|pop|top|min)\s*(.*)$/);
if (operator == "push") {stack . push (+value)}
if (operator == "pop") {stack . pop ()}
if (operator == "top") {
console . log (stack . length ? stack [stack . length - 1] : ERROR)
}
if (operator == "min") {
console . log (stack . length ? Math . min (... stack) : ERROR)
}
}
Note the use of the unary + operator, in +value. Since we have parsed value out of the string, value is a string. If we take the minimum of a set of strings, we get the first string in alphabetic order — which is not what we want. Unary plus returns a numerical value, so we’re pushing numbers on the stack, and get the smallest number when using min.
Node.js does not flatten arrays when passed into functions, but Math . min takes a list, not an array. Therefore, we use the spread (...) operator, which, when applied on an array, returns a list with the array elements.
Find the complete program on GitHub.
Python
Just like Perl and Node.js Python does have a push method, although they call it append. A pop method exists as well.
Python does have a min buildin, which can take an array as argument.
This leads to the following program:
import fileinput
stack = []
error = "Stack is empty"
for line in fileinput . input ():
chunks = line . split ()
command = chunks [0]
if command == "push":
stack . append (int (chunks [1]))
if command == "pop":
if len (stack):
stack . pop ()
if command == "top":
if len (stack):
print stack [len (stack) - 1]
else:
print error
if command == "min":
if len (stack):
print min (stack)
else:
print error
Find the complete program on GitHub.
AWK
AWK does not have a push operator. But it dynamically grows array, that is, if you add an element to an array, and the index doesn’t exist yet, AWK grows the array as needed. So we can simulate a push by just adding the pushed element to the first index after the largest current index.
To simulate pop, we make use of the delete function, which removes an element from an array.
There is no AWK buildin to get the minimum value of a list or array, so we have to iterate over the array, and find the minimum.
AWK programs automatically iterate over the input, executing blocks where preceding conditions are met:
BEGIN {error = "Stack is empty"}
{size = length (stack)}
A BEGIN block is executed once, before processing any input (if you are wondering where Perl got its BEGIN blocks from, the answer is AWK); this sets up an error message. The second block is executed for every line of input (there is no condition, which in AWK means, it’s always true). Here we store the current number of elements of the stack in the variable size, so we can refer to it in other blocks. Note that we do not have to declare variables.
Each of the four possible commands get their own block.
/^push/ {
split($0, a, / +/)
stack [size + 1] = a [2]
}
In AWK, the current line is in the variable $0. split works like split in Perl, but it has arguments in a different order. The first argument is the string to be split (here, the current line of input); the second argument is an array, in which the results are placed. The third argument is the pattern to split on. So, in the block, we split on whitespace, placing the command (which we already know is "push") in a [1], and the value to be pushed in a [2]. Note that in AWK, array indexes are 1-based.
We then assign the value to be pushed just passed the end of the current stack, in effect, pushing a value on the stack.
/^pop/ {
delete stack [size]
}
Remove the last element of the array stack.
/^top/ {
print size ? stack [size] : error
}
Print the last element of the array stack, or an error if the stack is empty.
/^min/ {
if (size) {
min = stack [1]
for (i = 2; i <= size; i ++) {
if (min > stack [i]) {
min = stack [i]
}
}
print min
}
else {
print error
}
}
Here we iterate over the array stack, finding the minimum value.
Find the complete program on GitHub.
C
As usual, C requires the most work. There are no push or pop operations, and arrays don’t automatically resize.
So, we will not be using an array. Instead, we will be using a linked list using records and pointers. Just like algorithms 101!
We will be using the following type and variable:
struct node {
long value;
struct node * next;
};
struct node * stack = NULL;
Our stack is pointer to a record; this record holds two elements: value, and next, where the former is a value pushed on the stack, and the latter a pointer to another record. We initialize the stack to NULL, indicating the stack is empty.
We iterate over the input, putting each line into the variable line. Then, we do our actions:
if (strncmp (line, "push", 4) == 0) {
long val;
if (sscanf (line + 4, " %ld", &val)) {
struct node * head;
head = (struct node *) malloc (sizeof (struct node));
if (head == NULL) {
fprintf (stderr, "Out of memory!\n");
exit (1);
}
head -> value = val;
head -> next = stack;
stack = head;
}
}
If we encounter a push command, we will be using sscanf to extract the value from the current line of input. We then create a new record by using malloc. In the new record, we set the just parsed value, and we let the new record point to the current stack. Finally, we update stack to point to the new record.
if (strncmp (line, "pop", 3) == 0 && stack != NULL) {
struct node * next;
next = stack -> next;
free (stack);
stack = next;
}
When we have to pop an element from the stack, we use a temporary variable next, which we set to the second element on the stack. We free stack, returning the memory, and then update stack.
if (strncmp (line, "top", 3) == 0) {
if (stack == NULL) {
printf ("%s\n", error);
}
else {
printf ("%ld\n", stack -> value);
}
}
This prints the top of the stack, or an error message if the stack is empty.
if (strncmp (line, "min", 3) == 0) {
if (stack == NULL) {
printf ("%s\n", error);
}
else {
long min = stack -> value;
struct node * pointer = stack -> next;
while (pointer != NULL) {
if (pointer -> value < min) {
min = pointer -> value;
}
pointer = pointer -> next;
}
printf ("%ld\n", min);
}
}
To find the minimum element of the stack, we have to walk through our linked list. Assuming the stack isn’t empty, we start with the top of the stack (first element of the linked list), and then walk the list by following the next pointer to the end. Each time we find an element which is less than the smallest element found so far, we remember it.
Find the complete program program on GitHub.
Perl Weekly Challenge 95, Part 1
You are given a number $N.
Write a script to figure out if the given number is a palindrome. Print 1 if true otherwise 0.
Overview
We could just use a one-liner (in Perl) $_ eq reverse $_, but there’s no fun in that. Instead, we’re upping the ante a little: we also want to check that we have a valid number.
What kind of number can be palindromes? Unsigned integers can: 121 and 7337 are examples. Signed numbers like -645 or +2300 cannot — they start with a sign (either - or +), but they don’t end with one, so they are not a palindrome.
Unsigned decimal numbers can be palindromes though, 1.1 and 70.07 are examples of that.
We also want to accept numbers written in digits from other scripts (assuming the programming language we are using has build in Unicode support). That is, we want to accept ๑๒๓๒๑ and ๑๒.๒๑ (we still assume an ASCII dot is used as decimal dot).
Ideally, we want to reject number like ๑௧๓௧๑ — although it is a palindrome, and the string consists of nothing but digits, it is mixing digits from different scripts. But not many languages have easy support for this.
Solutions
Perl
For our Perl solution, we construct a regular expression which recognizes palindromic numbers, where all the digits are in the same script.
We can define a numeric palindrome recursively:
- An empty string is a numeric palindrome, if it’s followed by a digit.
- A single digit is a numeric palindrome.
- A single dot is a numeric palindrome, if it’s followed by a digit.
- If a string which starts with a digit, ends with the same digit, and the remaining substring is a numberic palindrome, then the complete string is a numeric palindrome.
And the entire string should have all its digits in the same script.
We can then write the pattern to match a numeric palindrome as follows:
/^(*sr: # Start a script run
(?<PAL> # Start a group named "PAL"
\.?(?=\d) # Empty string, or a dot, followed by a digit
| \d # Or a single digit
| (\d) # Or a digit
(?&PAL) # ... followed by a palindrome
\g{-1} # ... and the same digit again
) # End of the "PAL" group
)$/x # End of the script run.
Script runs were introduced in Perl 5.28, and can be used to assert we don’t have mixing of scripts inside.
All that is left to do is match the input against the pattern above. Which can be seen in the full program on GitHub.
Node.js
For our Node.js solution, we don’t have a the ability to create recursive patterns, so we create a pattern to recognize an (unsigned) number; and have a separate check to see whether we have a palindrome. Node.js doesn’t have script runs either.
The default regex engine in Node.js does not have much Unicode support, so we will use xregexp instead.
Here is our pattern:
var XRegExp = require ('xregexp');
var pattern = XRegExp ('^\\p{Nd}+(?:\\.\\p{Nd}+)?$', 'u');
Node.js doesn’t have a string reversal operator; it does have method the reverse an array (reverse. Therefore, the reverse a string, we split in into individual characters, reverse the array with those characters, and then join it again.
This results in the following code, where _ holds the string we want to check whether it contains a numerical palindrome:
console . log (_ == _ . split ("")
. reverse ()
. join ("") &&
XRegExp . match (_, pattern) ? 1 : 0)
Find the complete program on GitHub.
Python
Like Node.js, Python doesn’t have recursive patterns, nor script runs. It does however have native Unicode support for its regexp engine, although it needs to be enabled with a parameter.
Just like the Node.js solution above, we use a regular expression to check whether the input is a number, and separate check to see whether the input is a palindrome.
If line contains the string we want to check, we use the following regular expression match to check whether we have an unsigned number:
re . match (r'^\d+(\.\d+)?$', line, re . UNICODE)
Python does not have a function to reverse a string. But it has a powerful way of taking using indexing on strings: it takes a start index (default the beginning of the string), an end index (defaults to the end of the string), and, optionally, a step parameter, which can be negative. If the step parameter is negative, we walk backwards. So line [::-1] is the reverse of the string line.
Combining those two things results in:
if (re . match (r'^\d+(\.\d+)?$', line, re . UNICODE) and
line == line [::-1]):
print 1
else:
print 0
Find the complete program on GitHub.
AWK
AWK doesn’t have native Unicode support, nor does it have recursive patterns. But it does have regular expressions, so again, we split the task into two: check for a valid unsigned number, and whether it is a palindrome.
AWK programs consist of a sequence of condition {block} statements. For each line of the input, we iterate over the statements, and execute the block if the condition is true. (A condition may be empty; if so, the block is always executed).
We start off by initializing a variable to zero:
{is_palindrome = 0}
Since the condition is empty, the block is always executed.
The next block checks whether we have a valid number, and if so, we check whether we have a palindrome:
/^[0-9]+(\.[0-9]+)?$/ {
is_palindrome = 1
for (i = 1; i <= length / 2; i ++) {
s1 = substr($0, i, 1)
s2 = substr($0, length - i + 1, 1)
if (s1 != s2) {
is_palindrome = 0
}
}
}
Checking whether the string is a palindrome starts by assuming it is (is_palindrome = 1). Then we iterate over the string, from start to middle, and end to middle, and check whether the corresponding characters are the same. If not, the string is not a palindrome. Note that strings (and arrays) in AWK are indexed starting from 1.
Printing the result is done in a third block — again with a block without a condition:
{print is_palindrome}
Find the complete program on GitHub.
C
In C, we have to work harder than in any of the other solutions. There are regular expressions in C (at least, not without an additional library), nor is there any native Unicode support.
So, we check whether the input we got is a palindrome, by matching characters from the beginning and end, and to assert that the matched characters are (ASCII) digits. If the string length is odd, the middle character must either be a digit, or a dot — but the latter is not allowed if the string length is 1.
We read lines of input using the method getline:
char * line = NULL;
size_t len = 0;
size_t str_len = 0;
while ((str_len = getline (&line, &len, stdin)) != -1) {
str_len --;
bool is_palindrome = !!str_len;
We are subtracting 1 from strlen, because we don’t want to match the trailing newline. A valid numerical palindrome must have at least one character, so if read line only contains a newline, we cannot have a valid palindrome.
We then check the all characters, except the middle one (if there is a middle one — if the string length is even, we check all character):
for (size_t i = 0; i < str_len / 2 && is_palindrome; i ++) {
if (line [i] < '0' || line [i] > '9' ||
line [i] != line [str_len - i - 1]) {
is_palindrome = false;
}
}
If either the character is not a digit, or the matching character from the end is different, we cannot have a palindrome.
Now we check the middle character, and print the result:
if (is_palindrome && str_len % 2) {
size_t mid = str_len / 2;
if ((line [mid] < '0' || line [mid] > '9') &&
(line [mid] != '.' || str_len == 1)) {
is_palindrome = false;
}
}
printf ("%d\n", is_palindrome ? 1 : 0);
Find the full program on GitHub.
